🚀 Building a Production-Grade Python Logging SDK for Distributed Observability
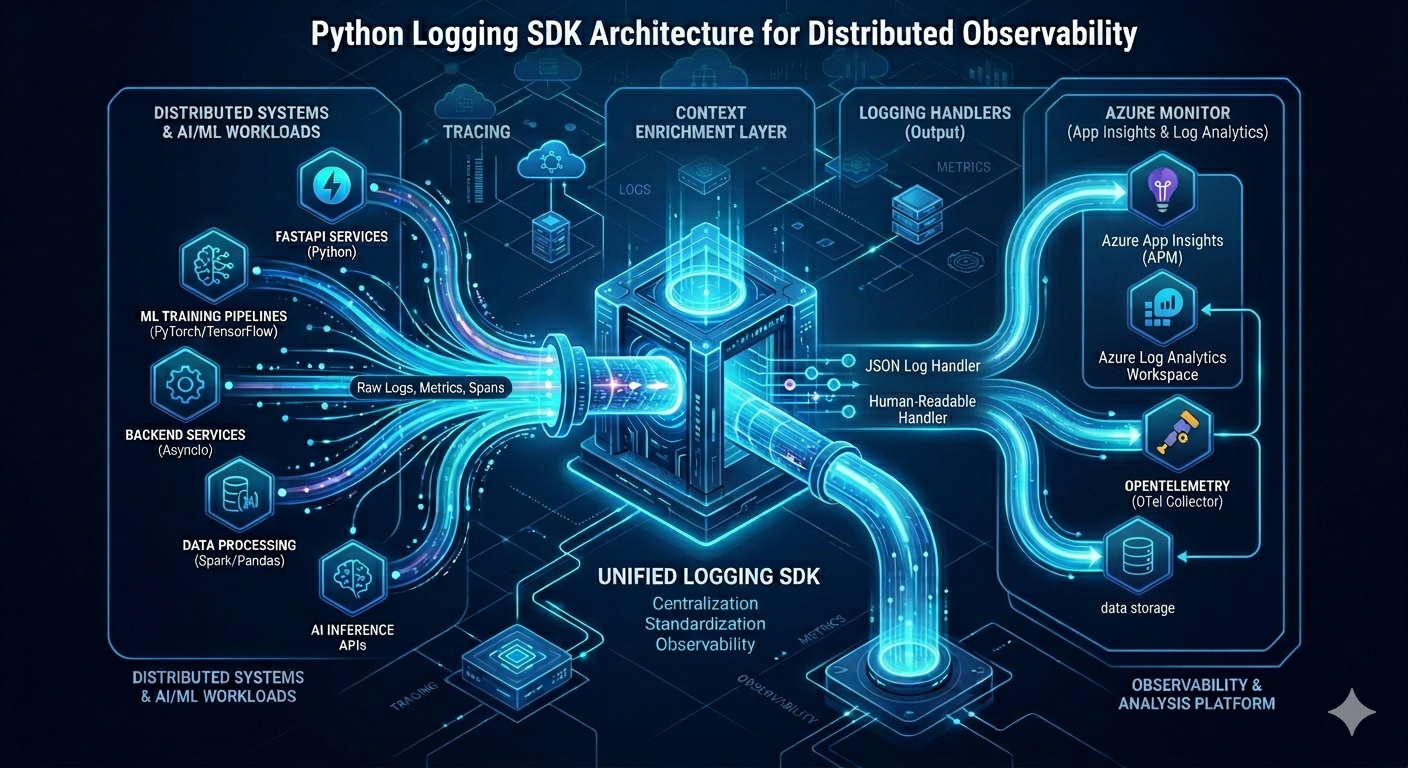
Over the last few days, I've built a lightweight, plug-and-play logging SDK for Python that standardizes observability across AI/ML, backend, and distributed systems.
🎯 The Problem
One of the most overlooked problems in engineering teams — inconsistent logging across services.
As teams grow, every developer implements their own logging style. Logs are unstructured, context is missing, sensitive data leaks into outputs, and debugging a distributed failure becomes a nightmare.
Just import the SDK, and every service automatically gets structured, context-aware logs with minimum setup.
💭 The insight: Logging isn't just a utility — it's an engineering standard. When logs are inconsistent, your observability is broken before an incident even starts.
✨ Why This Matters — Problems It Solves
- 🔍 Log fragmentation → Every service logs differently, making cross-service debugging painful
- 🕵️ Missing context → Logs without trace IDs or request IDs are useless in distributed systems
- 🔒 Security gaps → Sensitive data (tokens, secrets, keys) accidentally logged in plaintext
- ⚡ Developer friction → Every project reinvents the logging boilerplate
- 🌐 Observability gaps → AI/ML pipelines often have zero structured logging
🛠 Stack & Technologies
- 💻 Language: Python 3.10+
- 🧱 Logging Engine: Custom structured logging core
- 🔗 Context Layer: Async-local context propagation
- 📄 Output Formats: JSON + human-readable logs
- 🔒 Security: Automatic sensitive data redaction (secrets, tokens, keys)
- 📊 Observability: Correlation IDs —
trace_id,request_id,span_idsupport - ☁️ Integration: Works locally and with Azure-based observability systems, OpenTelemetry-compatible
- ⚙️ Environment Config: Dev / CI / Prod-aware logging behaviour
💎 Key Advantages Over Traditional Logging
| Traditional Logging | This SDK | |
|---|---|---|
| Log format | Inconsistent per service | Unified structured JSON |
| Context injection | Manual, often missing | Automatic per request |
| Sensitive data | Risk of accidental exposure | Built-in redaction |
| Distributed tracing | Manual correlation | trace_id + request_id built-in |
| Environment config | Hand-coded per project | Auto-configured by env |
| Setup effort | Boilerplate per project | Just import and use |
- ✅ Standardized Logs: Every service follows the same structured format
- ✅ Context-Aware: Automatic injection of system + request metadata
- ✅ Traceability: Full end-to-end correlation across distributed systems
- ✅ Secure by Default: Built-in sensitive data redaction
- ✅ Zero Friction: Just import and use — no boilerplate setup
- ✅ Framework Agnostic: Works across ML pipelines, APIs, and backend services
💡 What This Unlocks
- ⏱ Faster debugging across distributed systems
- 🛡 Eliminates log fragmentation across teams
- 🔍 Improves observability in AI/ML workflows
- ⚡ Reduces production incident resolution time
- 📐 Creates a consistent engineering standard across projects
This logging SDK isn't just a utility — it's an engineering standard that makes every Python service observable, traceable, and production-safe from day one.