Local-First AI Security Auditor: Evidence, Not Excuses
🚨 Local-First Security Auditing for DevOps & AI/ML Engineers | Evidence, Not Excuses
We run:
🧪 SAST scans
📦 Dependency checks
🏗️ Infra / IaC security scans
🧰 Custom vulnerability scripts
…and still struggle to answer:
👉 “What are the actual risks across everything?”
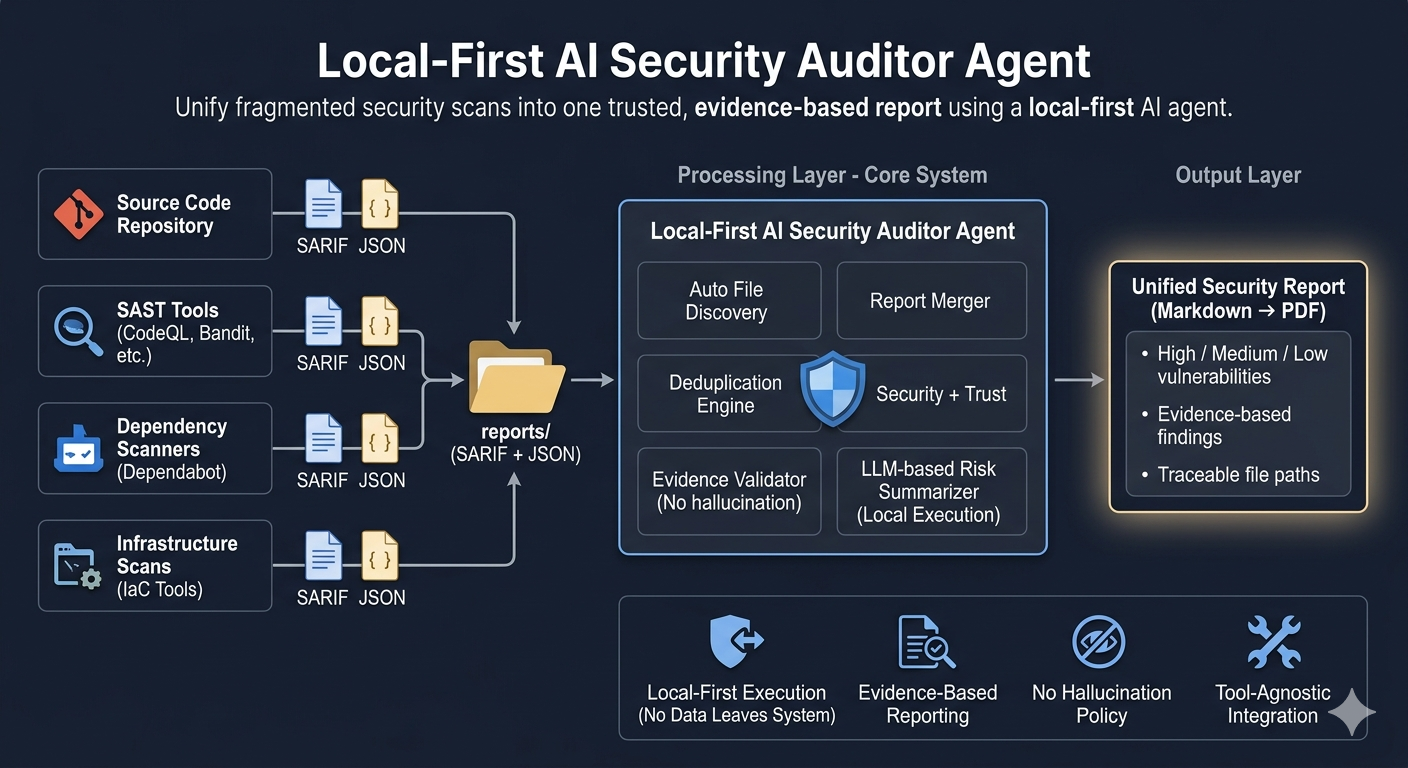
The Real Problem: Fragmentation
Each tool speaks a different language:
- 📄 SARIF from SAST tools
- 📊 JSON from dependency scanners
- 🔁 Overlapping + duplicate findings everywhere
- 🧩 No single unified security view
So we end up:
- 🧵 Manually stitching reports
- ❌ Missing duplicated or conflicting issues
- 📉 Sharing outputs we don’t fully trust
Solution: A normalization + synthesis layer for everything we already run.
What It Does
- 📥 Ingests SARIF / JSON from any tool
- 🔗 Merges findings across code, dependencies, infra, configs
- 🧹 Deduplicates overlapping vulnerabilities
- 📄 Outputs a single Markdown report (PDF-ready)
- 🔎 Every issue is backed by real, traceable evidence
Key Principle
Most AI security tools fail because they hallucinate. This system is designed so that:
- 📂 Only real repo files are passed to the model
- 📊 Only actual scan outputs are used
- 🚫 Rule: no evidence → no output
👉 If it’s not in your data, it doesn’t exist in the report.
Sample Output
🚨 HIGH: Hardcoded API Key
📁 File: repo/config.js:12
🔧 Tool: Bandit
⚠️ Impact: Unauthorized API access
⚠️ MEDIUM: Outdated dependency (requests 2.19)
🔧 Tool: Dependabot
ℹ️ LOW: Debug mode enabled
📁 File: app/settings.py
Why Not Just Use SAST or Copilot?
🧪 SAST → produces isolated findings
🤖 Copilot → gives suggestions in context
But neither gives: 👉 a unified, evidence-backed security view
What This System Actually Is
- 🧩 Tool-agnostic aggregation layer
- 🧠 LLM-powered summarisation engine
- 📊 Deterministic, evidence-based reporting
- 🏠 Fully local-first execution
What Actually Matters
- ⚠️ Without strict constraints, LLMs WILL invent vulnerabilities
- 🧹 Deduplication matters more than detection noise
- 📂 File-level grounding changes report accuracy completely
- 🔐 Local-first = control, auditability, zero data leakage
- 🎯 Teams don’t need more findings — they need clarity + proof
What’s Next: Multi-Agent Orchestration
🕵️ Security Analysis Agent
📁 Repo Intelligence Agent
📊 Risk Synthesis Agent
Orchestrated via OpenAI Agents SDK for deeper, structured analysis.
This isn’t about running more scans. It’s about turning fragmented outputs into something you can actually trust, trace, and act on.