Building an AI Decision Engine with Mistral, FastAPI & PromptFlow
Rules-based systems are powerful but brittle — they tell you the outcome, not the why. AI reasoning systems are flexible but opaque. What if you combined both?
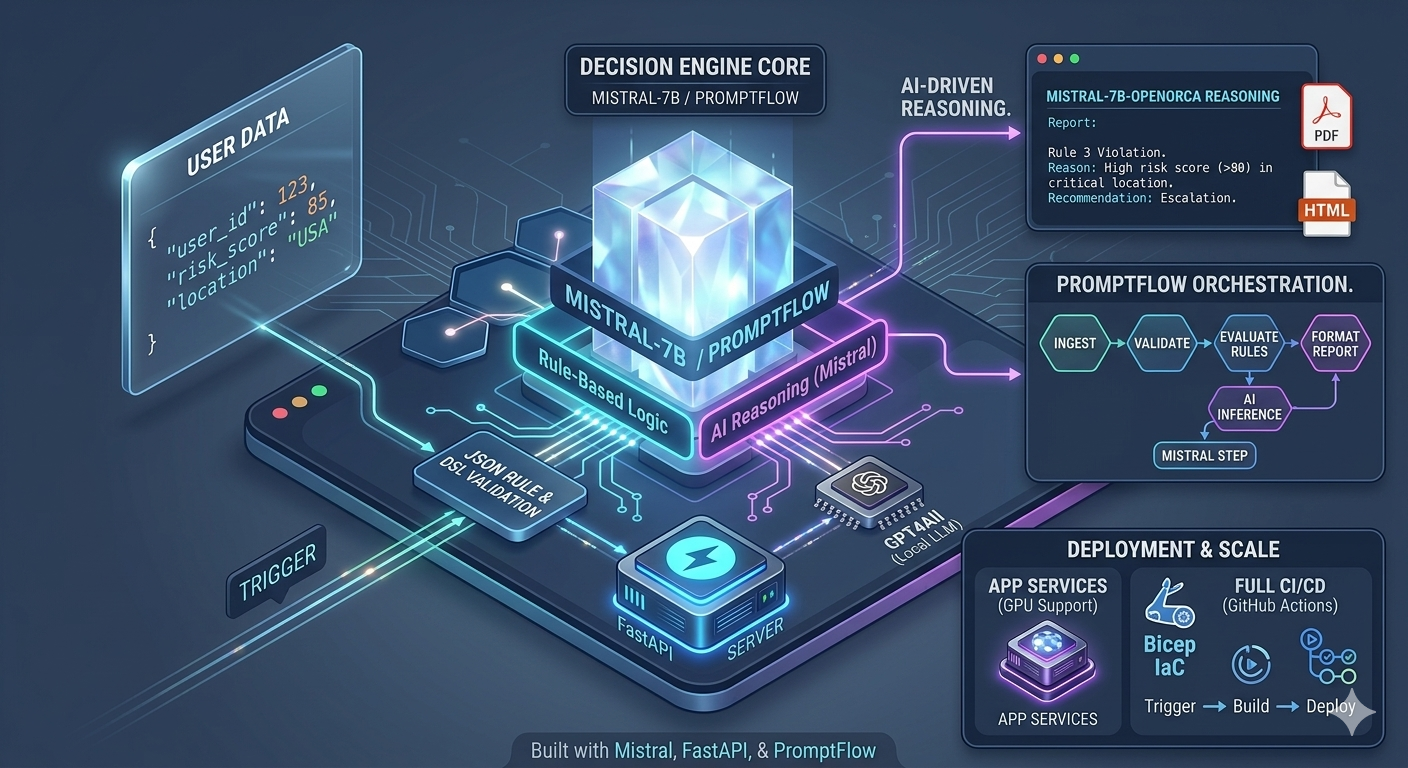
I built a dynamic decision engine that evaluates user data against rules defined in JSON and adds AI-powered reasoning to explain the result in plain language. No black-box decisions — every outcome comes with a human-readable explanation.
💡 What It Does
- Loads decision rules from JSON — no code changes needed to update logic
- Evaluates user-submitted data against those rules at runtime
- Passes matched rule context to Mistral-7B-OpenOrca via GPT4All for natural language reasoning
- Returns structured decisions with AI-generated explanations
- Produces HTML and PDF reports for each evaluation
- Orchestrates the full workflow with PromptFlow
⚙️ Tech Stack
| Layer | Technology |
|---|---|
| API server | FastAPI + Uvicorn |
| Rule engine | JSON-based DSL (custom) |
| Local LLM reasoning | Mistral-7B-OpenOrca via GPT4All |
| Workflow orchestration | PromptFlow |
| Report generation | Jinja2 + WeasyPrint |
| Infrastructure | Azure App Services (GPU-enabled) |
| IaC | Bicep |
| CI/CD | GitHub Actions |
🔧 How It Works
1. Rules as JSON
Decision logic lives in structured JSON files — no hard-coded conditionals. Rules define conditions, thresholds, and outcomes. This makes the engine configurable without redeployment.
{
"rule_id": "income-check",
"condition": "annual_income < 30000",
"outcome": "ineligible",
"reason_prompt": "Explain why this applicant does not meet the income threshold."
}
2. FastAPI Endpoints
Multiple endpoints handle different entry points:
POST /evaluate— JSON API for programmatic evaluationPOST /evaluate/form— HTML form submission for human usersGET /report/{id}— retrieve a generated HTML or PDF report
3. AI Reasoning with Mistral
Once a rule matches, the engine constructs a prompt with the rule context and the user's data, then calls Mistral-7B-OpenOrca locally via GPT4All. The model returns a concise, plain-English explanation of the decision.
Running the LLM locally keeps sensitive applicant data entirely on-premises — no external API calls, no data transmitted.
4. PromptFlow Orchestration
PromptFlow ties the steps together — rule evaluation, LLM reasoning, report generation — as a traceable, debuggable workflow. This makes it easy to replay, inspect, and improve individual steps without running the full pipeline.
5. PDF Reports
Each evaluation generates a branded HTML report rendered to PDF with WeasyPrint. Reports include the decision outcome, matched rules, AI reasoning, and a timestamp — ready for auditing or end-user delivery.
☁️ Deployment
The engine is deployed on Azure App Services with GPU support for the LLM inference step. Infrastructure is defined entirely in Bicep, making environment provisioning reproducible and version-controlled.
The GitHub Actions CI/CD pipeline handles:
- Lint and unit tests on PR
- Docker build and push to ACR on merge
- Automated deployment to App Service
📘 What I Learned
Rule-based logic + AI reasoning is a strong pattern
Pure rule engines are fast and auditable but can't explain nuance. Pure LLMs are flexible but hard to constrain. Combining them gives you the best of both: deterministic outcomes with intelligible reasoning.
PromptFlow adds real observability to LLM workflows
Rather than chaining calls in ad-hoc Python, PromptFlow structures each step as a node with inputs, outputs, and traces. This made debugging and iteration significantly faster.
GPU-backed App Services close the gap between prototype and production
Running a 7B parameter model in a cloud environment with GPU support made latency viable for real user-facing use cases — without needing to manage Kubernetes or custom VM infrastructure.
The combination of rule-based certainty and AI-generated reasoning makes decisions more transparent and defensible — critical for any system that affects real people.
Related Topics
- PromptFlow — Microsoft's LLM workflow orchestration framework for Azure AI
- GPT4All — cross-platform runtime for running open-source LLMs locally
- Mistral-7B — efficient open-source LLM well-suited for reasoning tasks
- Azure App Service (GPU) — managed hosting with GPU support for ML workloads
- Bicep — Azure-native IaC language for declarative resource provisioning